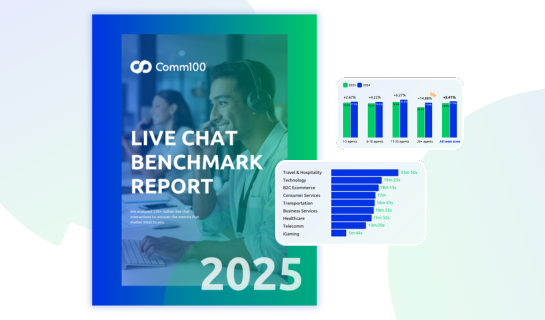
It’s live! Access exclusive 2025 live chat benchmarks & see how your team stacks up.
Get the dataIt’s live! Access exclusive 2025 live chat benchmarks & see how your team stacks up.
Get the dataConnect. Engage. Empower.
Build stronger relationships, boost team performance, and harness AI to improve the quality of your conversations.



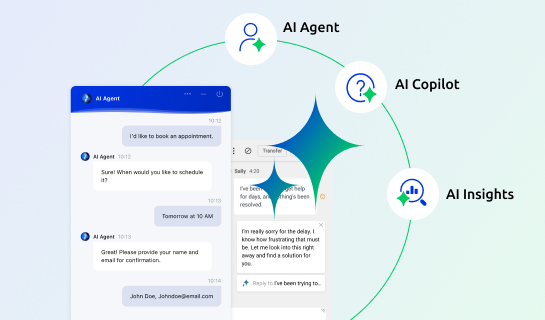
Let the Comm100 AI Agent handle up to 80% of routine conversations, reducing agent workload.
Complex queries are seamlessly escalated to live chat agents for streamlined personalized support.
Empower your agents with AI Copilot — our advanced suggestion engine that delivers context-aware guidance in real time.
Enhance response quality and bridge communication gaps with multilingual support across 90+ languages.
Easily wrap up chats with AI Copilot and provide internal comments for comprehensive context and knowledge sharing.
Categorize interactions — like inquiries, feedback, and complaints — to inform training, identify trends, and generate tickets for critical issue resolution.
Securing sensitive customer data processed by Comm100 Live Chat is a top priority.
We adhere to stringent, industry-leading standards — including SOC 2, ISO 27001, HIPAA, and GDPR — and implement robust safeguards such as encryption and role-based access control across the platform.
“We knew that we weren’t reaching a whole demographic profile because we were only offering phone and email support. If we wanted to connect with these potential donors, we had to provide them with a digital channel that was convenient and instant — and live chat was the obvious answer.”
– Denny Michaud, Customer Relations Manager, Canadian Blood Services
Agent
Experience
Manager
Experience
Visitor
Experience
Optimized for Performance
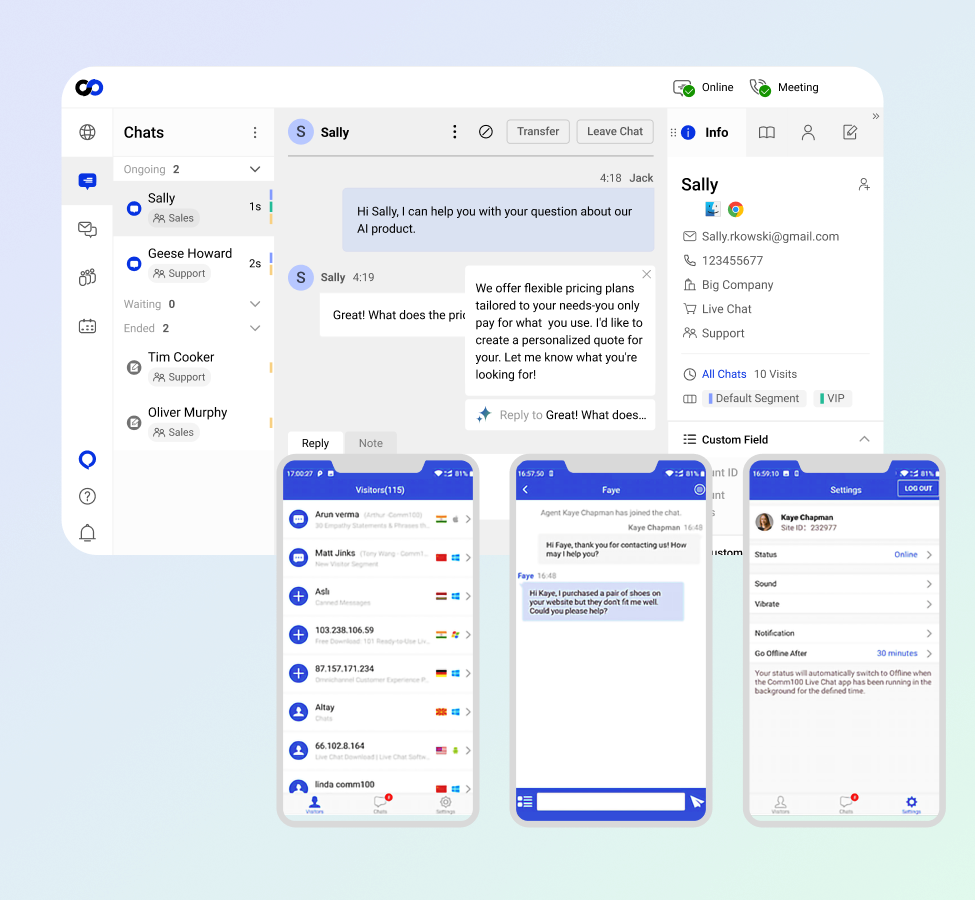
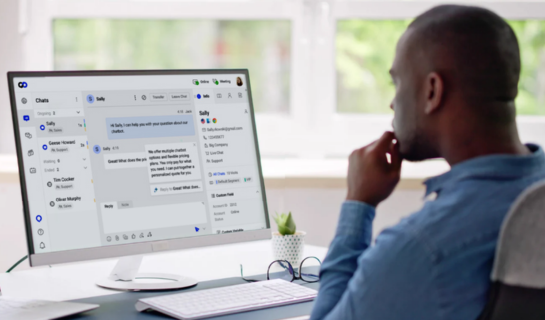
Work seamlessly across devices, channels, and platforms and efficiently manage customer interactions with Comm100’s Agent Console.
Access all conversations, visitor details, and chat history in one unified, easy-to-navigate view to boost productivity.
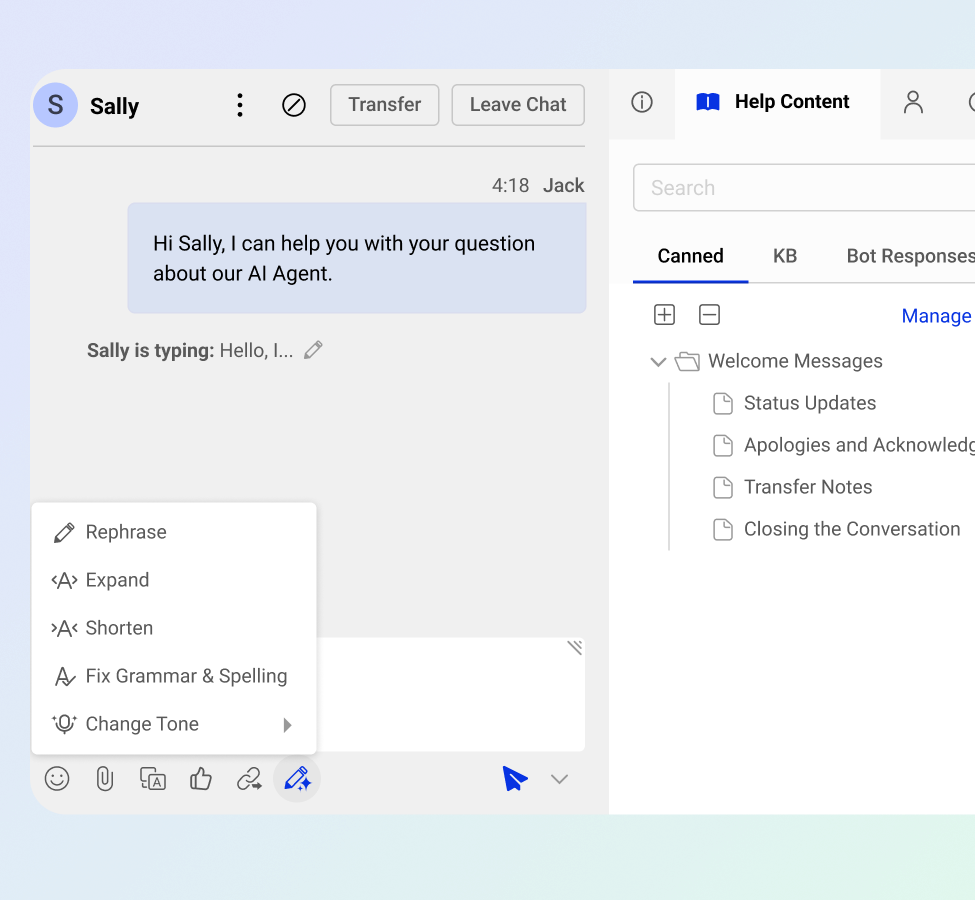
Proactively assist customers by previewing messages in real time and instantly searching your knowledge base for accurate answers.
Improve response accuracy and consistency with AI Copilot, delivering context-aware suggestions and helping agents rephrase, expand, summarize, or adjust tone for improved conversation quality.
Reduce response time with keyboard shortcuts, canned messages, and other time-saving features.


Powered by Data for Better Results

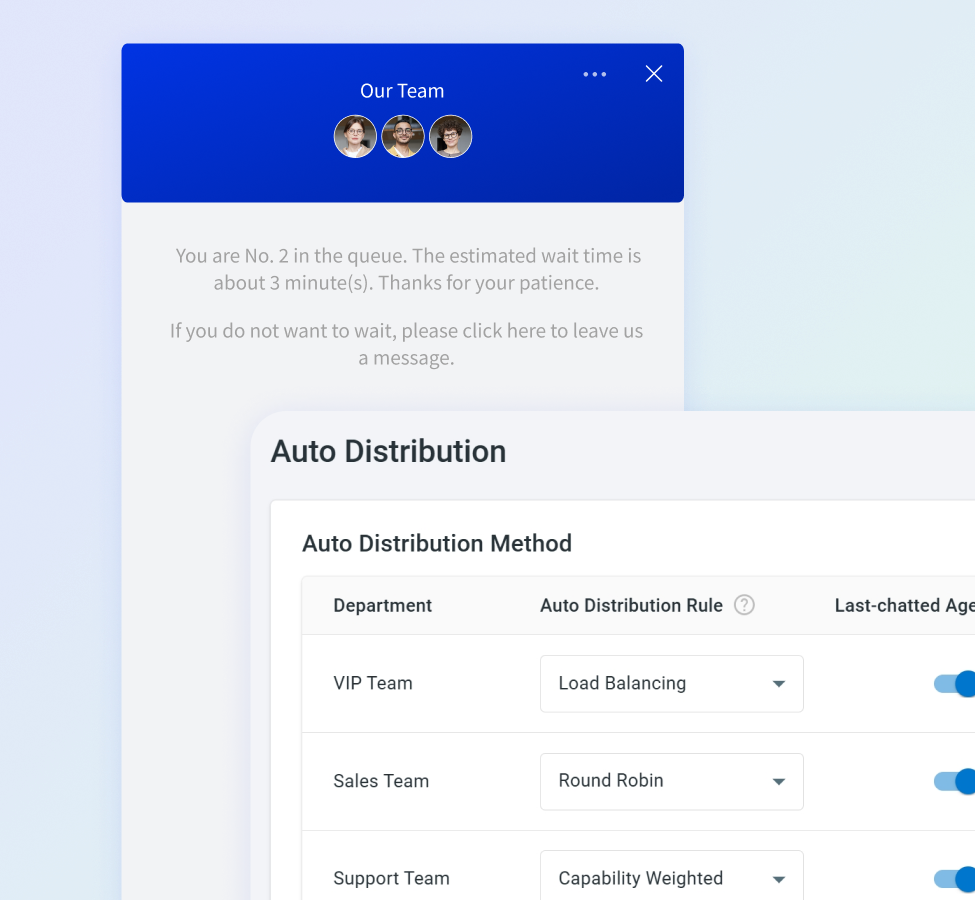
Optimize chat distribution using load balancing, capability weighting, and round-robin methods for efficient agent utilization.
Minimize visitor wait times with smart queue management. Proactively inform and notify visitors throughout the process, enhancing their experience and reducing frustration.
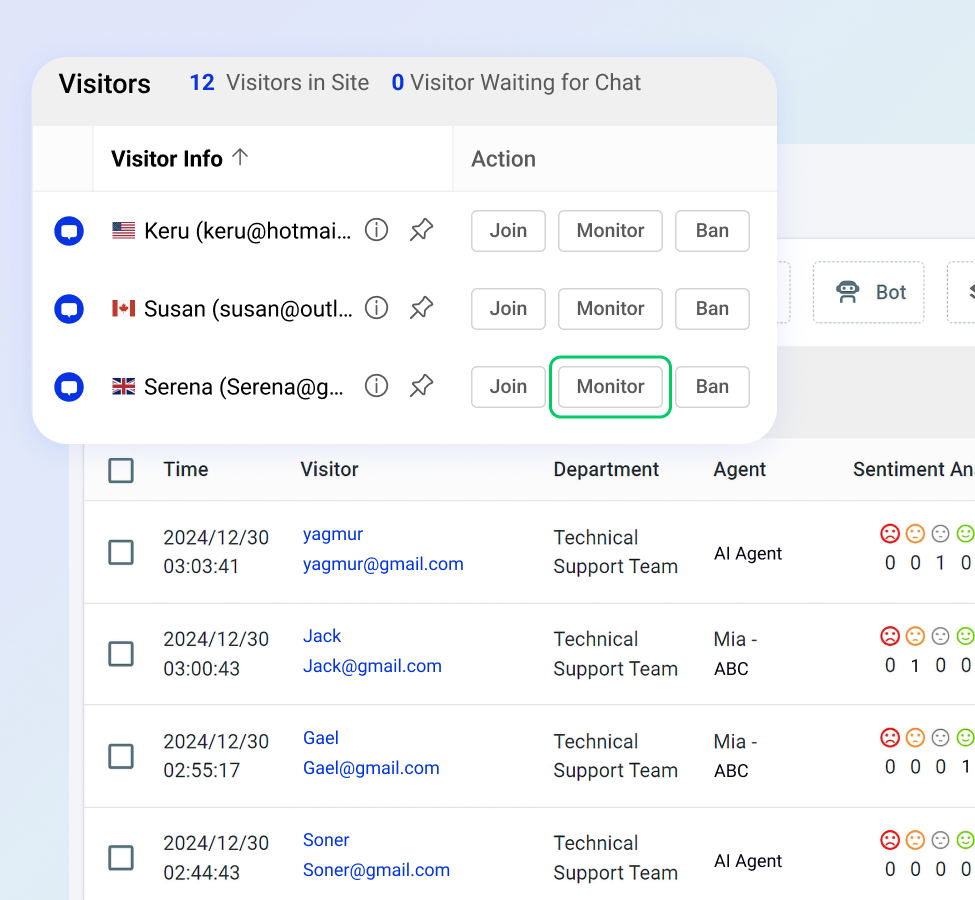

Utilize detailed reporting to track chat volumes and queue performance, evaluate agent efficiency, and optimize staffing based on wait times, peak hours, and chat transfer trends.
Leverage AI Insights to identify frustrated or disengaged customers for timely intervention, filter chats by sentiment to enhance coaching, and prioritize conversations by resolution status to quickly resolve issues and optimize resources — all empowering smarter business decisions.
Personalized for Maximum Satisfaction

Gain complete control over the appearance of your chat window and button. Choose from different styles, colors, and backgrounds, or use your own CSS.
Dynamically adapt chat designs for targeted visitor segments or websites to create a unique brand experience.
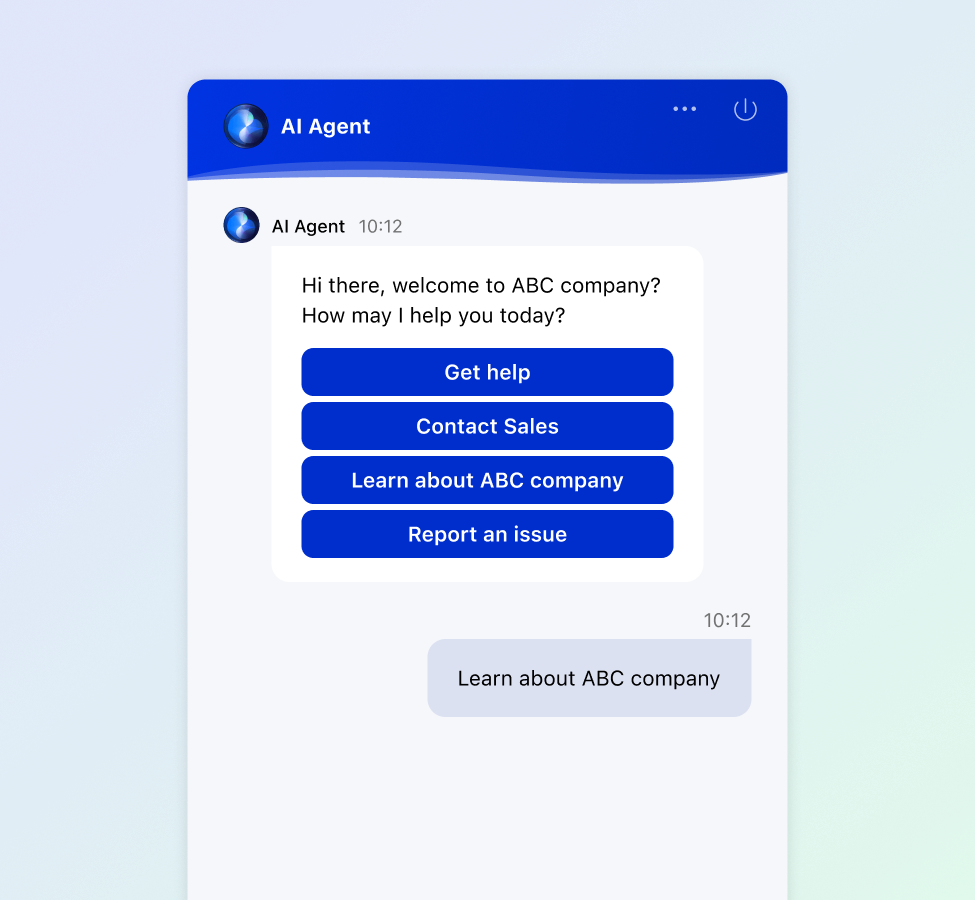
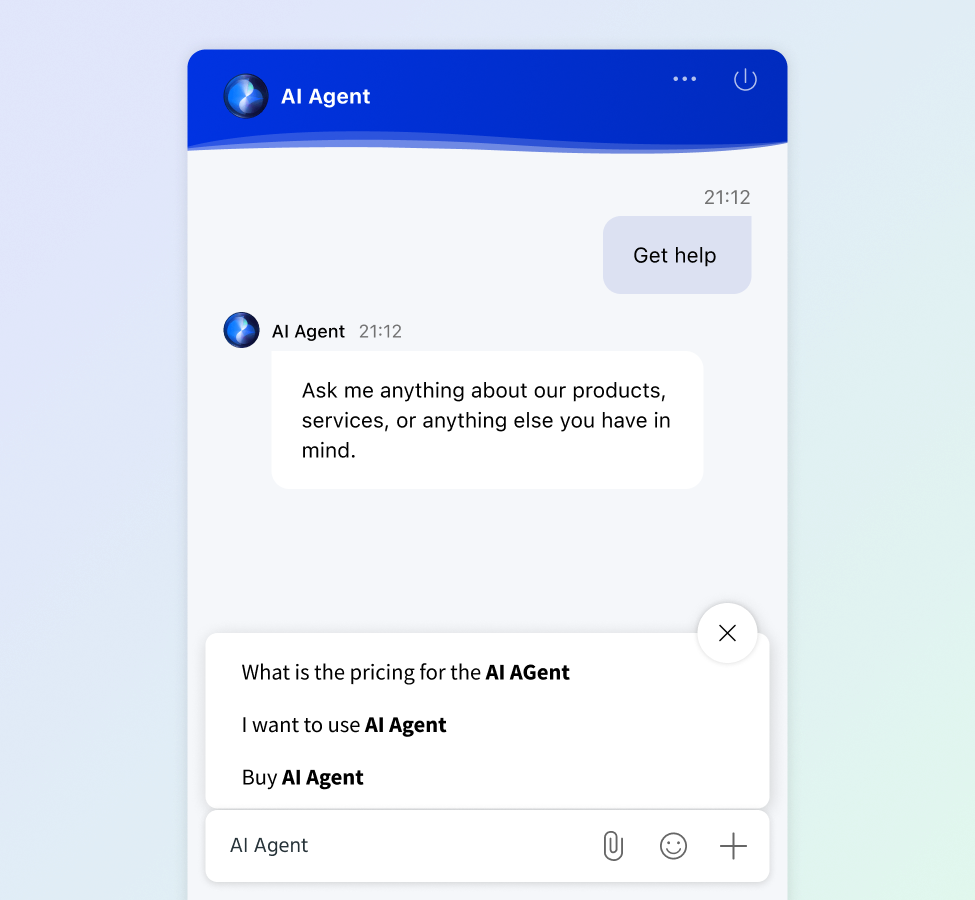
Let the Comm100 AI Agent step in when live agents are unavailable, collecting specific visitor information with human-like responses.
The AI Agent can seamlessly direct visitors to the right contact forms and automatically forward email transcripts to the designated recipients.
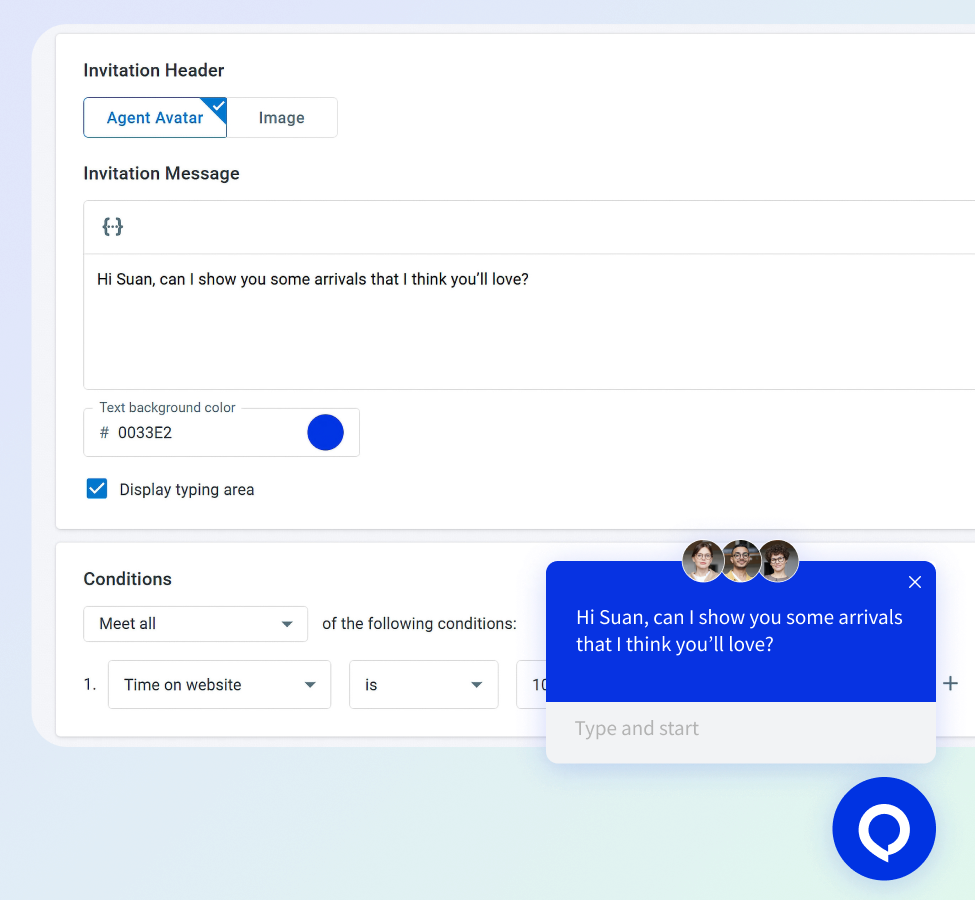
Initiate personalized visitor interactions with manual or rule-based automated invitations.
Choose from a variety of invitation styles, enrich with custom images and messages, and optimize customer engagement.
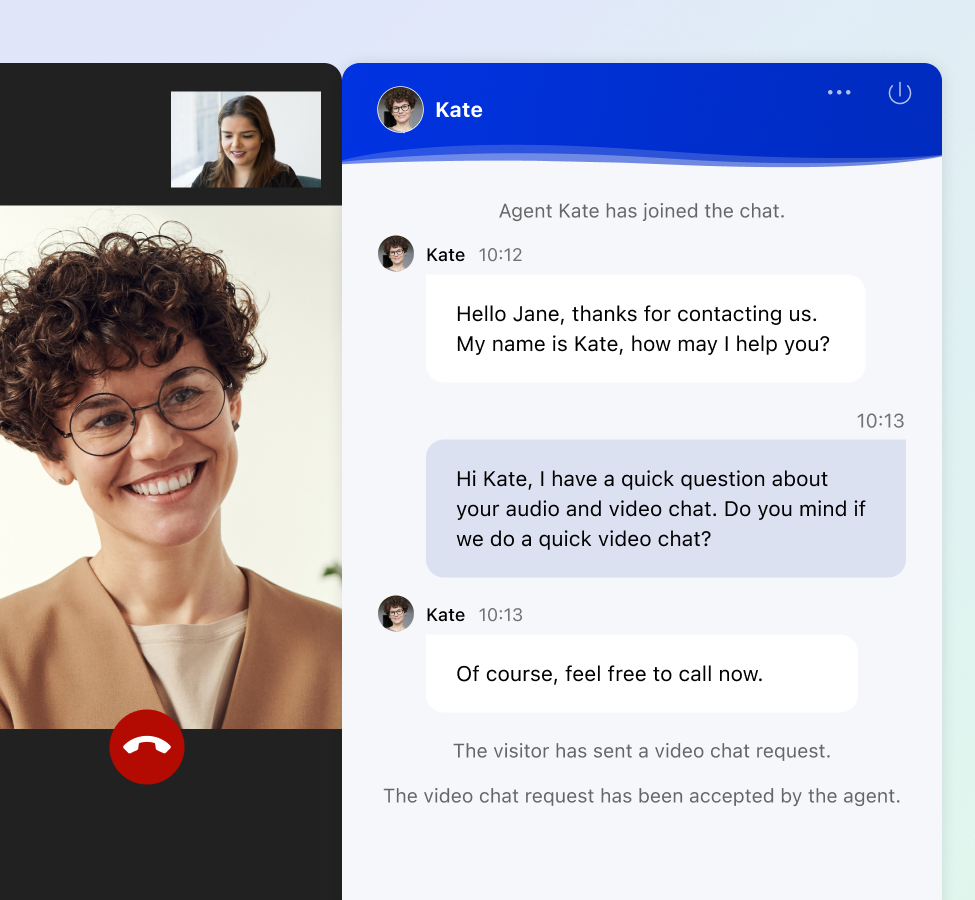
When a text chat isn't sufficient, seamlessly transition to audio or video calls for personalized support.
Accelerate resolutions with screen sharing and share files directly within the chat window for faster information exchange.
“With Comm100 Live Chat combined with Comm100 Chatbot (now AI Agent), we can now deliver fast, efficient, 24/7 support that helps us engage with more prospective students and provide better support.”
– Victoria Anderson
Manager, Admission Operations, Undergraduate Admission and Recruitment, Queen’s University
1 Day
Deployment Period
ROI can begin< 4 weeks
4.2/5
Average CSAT
Reported across all verticals
23 Sec
Average Wait Time
Connect faster with your visitors
80+
Live Chat Features
15+
Integrations Supported
17+
Detailed Reports
Automate 80% of customer queries with context-aware human-like AI responses
Supercharge human agents with real-time AI suggestions and automated workflows
Gain deep visibility into chat resolutions, sentiments, and other AI-driven analytics
Email, social media, SMS and more – all from one platform
Easy-to-find help resources for both customers and agents
Engage with customers via inbound and outbounds calls
Streamline the queueing experience to cut wait times & improve CX
Empower customers to book appointments or meetings with ease
Expand your knowledge and improve your team’s performance with our in-depth guides, best practices, and tools.
White Paper
What Makes a Top-Tier Customer Service Platform in 2025? 5 Key Features to Look for

See how our live chat can transform your business. Contact our sales team today!